금융을 따라 흐르는 블로그
파이썬 웹 크롤러 - naver news crawling 본문
0. 목적 : 원하는 기간에 네이버 뉴스 메인에 게시되었던 기사들만 골라서 제목 및 링크 수집
1. 수집 기간 정의하기
<파이썬의 기본 패키지 중 하나인 datetime을 사용>
import datetime
days_range = []
start = datetime.datetime.strptime("2015-02-25", "%Y-%m-%d")
end = datetime.datetime.strptime("2015-03-31", "%Y-%m-%d") # 범위 + 1
date_generated = [start + datetime.timedelta(days=x) for x in range(0, (end-start).days)]
for date in date_generated:
days_range.append(date.strftime("%Y-%m-%d"))
print(days_range)
['2015-02-25', '2015-02-26', '2015-02-27', '2015-02-28', '2015-03-01', '2015-03-02', '2015-03-03', '2015-03-04', '2015-03-05', '2015-03-06', '2015-03-07', '2015-03-08', '2015-03-09', '2015-03-10', '2015-03-11', '2015-03-12', '2015-03-13', '2015-03-14', '2015-03-15', '2015-03-16', '2015-03-17', '2015-03-18', '2015-03-19', '2015-03-20', '2015-03-21', '2015-03-22', '2015-03-23', '2015-03-24', '2015-03-25', '2015-03-26', '2015-03-27', '2015-03-28', '2015-03-29', '2015-03-30']
2. Html parser 정의하기
<원하는 페이지의 html에 접근하기 위해, parser을 정의>
!pip install bs4
>>>설치 결과 (Fail)
Collecting bs4 Downloading bs4-0.0.1.tar.gz (1.1 kB) Requirement already satisfied: beautifulsoup4 in ./opt/anaconda3/lib/python3.8/site-packages (from bs4) (4.9.3) Requirement already satisfied: soupsieve>1.2; python_version >= "3.0" in ./opt/anaconda3/lib/python3.8/site-packages (from beautifulsoup4->bs4) (2.0.1) Building wheels for collected packages: bs4 Building wheel for bs4 (setup.py) ... done Created wheel for bs4: filename=bs4-0.0.1-py3-none-any.whl size=1273 sha256=74a2154c141de013cf3e38aecda818f6a334175d64d86f4d5fda1dc1654c34b3 Stored in directory: /Users/iseunghun/Library/Caches/pip/wheels/75/78/21/68b124549c9bdc94f822c02fb9aa3578a669843f9767776bca Successfully built bs4 Installing collected packages: bs4 Successfully installed bs4-0.0.1
>>>설치 결과(Success)
Requirement already satisfied: bs4 in ./opt/anaconda3/lib/python3.8/site-packages (0.0.1) Requirement already satisfied: beautifulsoup4 in ./opt/anaconda3/lib/python3.8/site-packages (from bs4) (4.9.3) Requirement already satisfied: soupsieve>1.2; python_version >= "3.0" in ./opt/anaconda3/lib/python3.8/site-packages (from beautifulsoup4->bs4) (2.0.1)
import requests
from bs4 import BeautifulSoup
def get_bs_obj(url):
result = requests.get(url)
bs_obj = BeautifulSoup(result.content, "html.parser")
return bs_obj
3. 뉴스 페이지 수 구하기
<페이지 수 주변의 html 코드를 가져온 후, Python의 기본 함수인 split() 으로 쪼개어, 원하는 부분만 출력>
from tqdm import tqdm_notebook
test = ["2015-03-01"] # 테스트를 위한 데이터 수집 구간
for date in tqdm_notebook(test):
news_arrange_url = "https://news.naver.com/main/history/mainnews/list.nhn"
news_list_date_page_url = news_arrange_url + "?date=" + date
# get bs_obj
bs_obj = get_bs_obj(news_list_date_page_url)
# 포토 뉴스 페이지 수 구하기
photo_news_count = bs_obj.find("div", {"class": "eh_page"}).text.split('/')[1]
photo_news_count = int(photo_news_count)
print(photo_news_count)
# 리스트 뉴스 페이지 수 구하기
text_news_count = bs_obj.find("div", {"class": "mtype_list_wide"}).find("div", {"class": "eh_page"}).text.split('/')[1]
text_news_count = int(text_news_count)
print(text_news_count)
>>>결과(Fail)
File "<ipython-input-57-2d6864bceb2b>", line 5 news_arrange_url = "https://news.naver.com/main/history/mainnews/list.nhn" ^ IndentationError: expected an indented block
>>>결과(Fail)
<ipython-input-75-b5466524ffa1>:4: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0 Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook` for date in tqdm_notebook(test):
100%
1/1 [00:00<00:00, 42.31it/s]
4. 뉴스 정보 수집하기
<text_news_count 으로 페이지 수를 저장하였던 텍스트 기사에 대한 데이터 수집>
<모든 수집된 데이터는 main_news_list 라는 이름의 리스트에 차례대로 append 되도록 설정>
from tqdm import tqdm_notebook
from pprint import pprint
test = ["2015-03-01"]
main_news_list = []
for date in tqdm_notebook(test):
news_arrange_url = "https://news.naver.com/main/history/mainnews/list.nhn"
news_list_date_page_url = news_arrange_url + "?date=" + date
# get bs_obj
bs_obj = get_bs_obj(news_list_date_page_url)
# 포토 뉴스 페이지 수 구하기
photo_news_count = bs_obj.find("div", {"class": "eh_page"}).text.split('/')[1]
photo_news_count = int(photo_news_count)
# 리스트 뉴스 페이지 수 구하기
text_news_count = bs_obj.find("div", {"class": "mtype_list_wide"}).find("div", {"class": "eh_page"}).text.split('/')[1]
text_news_count = int(text_news_count)
# 포토 뉴스 부분 링크 크롤링
for page in tqdm_notebook(range(1,photo_news_count+1)):
# 포토 뉴스 링크
news_list_photo_url = 'http://news.naver.com/main/history/mainnews/photoTv.nhn'
date_str = "?date="
page_str = "&page="
news_list_photo_full_url = news_list_photo_url + "?date=" + date + "&page=" + str(page)
# get bs obj
photo_bs_obj = get_bs_obj(news_list_photo_full_url)
# 링크 내 정보 수집
ul = photo_bs_obj.find("ul", {"class": "edit_history_lst"})
lis = ul.find_all("li")
for item in lis:
title = item.find("a")["title"]
press = item.find("span", {"class" : "eh_by"}).text
# link
link = item.find("a")["href"]
sid1 = link.split('&')[-3].split('=')[1]
oid = link.split('&')[-2].split('=')[1]
aid = link.split('&')[-1].split('=')[1]
# 연예 TV 기사 제외
if sid1 == "shm":
continue
article_type = "pic"
pic_list = [date, article_type, title, press, sid1, link, aid]
main_news_list.append(pic_list)
# 텍스트 뉴스 부분 링크 크롤링
for page in tqdm_notebook(range(1, text_news_count+1)):
# 텍스트 뉴스 링크
news_list_text_url = 'http://news.naver.com/main/history/mainnews/text.nhn'
date_str = "?date="
page_str = "&page="
news_list_text_full_url = news_list_text_url + "?date=" + date + "&page=" + str(page)
# get bs obj
text_bs_obj = get_bs_obj(news_list_text_full_url)
# 링크 내 정보 수집
uls = text_bs_obj.find_all("ul")
for ul in uls:
lis = ul.find_all("li")
for item in lis:
title = item.find("a").text
press = item.find("span", {"class" : "writing"}).text
# link
link = item.find("a")["href"]
sid1 = link.split('&')[-3].split('=')[1]
oid = link.split('&')[-2].split('=')[1]
aid = link.split('&')[-1].split('=')[1]
# 연예 TV 기사 제외
if sid1 == "shm":
continue
article_type = "text"
text_list = [date, article_type, title, press, sid1, link, aid]
main_news_list.append(text_list)
pprint(main_news_list, width = 20)
File "<ipython-input-58-6daaa4b0ac1f>", line 8 news_arrange_url = "https://news.naver.com/main/history/mainnews/list.nhn" ^ IndentationError: expected an indented block
5. CSV파일로 저장하기
<수집한 정보를 관리하기 쉽도록 적절한 형태로 저장>
<csv file을 만들기 위해, 데이터를 다루는 데에 매우 편리한 패키지인 pandas를 사용>
import pandas as pd
# make .csv file
naver_news_df = pd.DataFrame(main_news_list,
columns = ["date", "type", "title", "press", "category", "link", "aid"])
naver_news_df.to_csv("naver_main_news.csv", index=False)
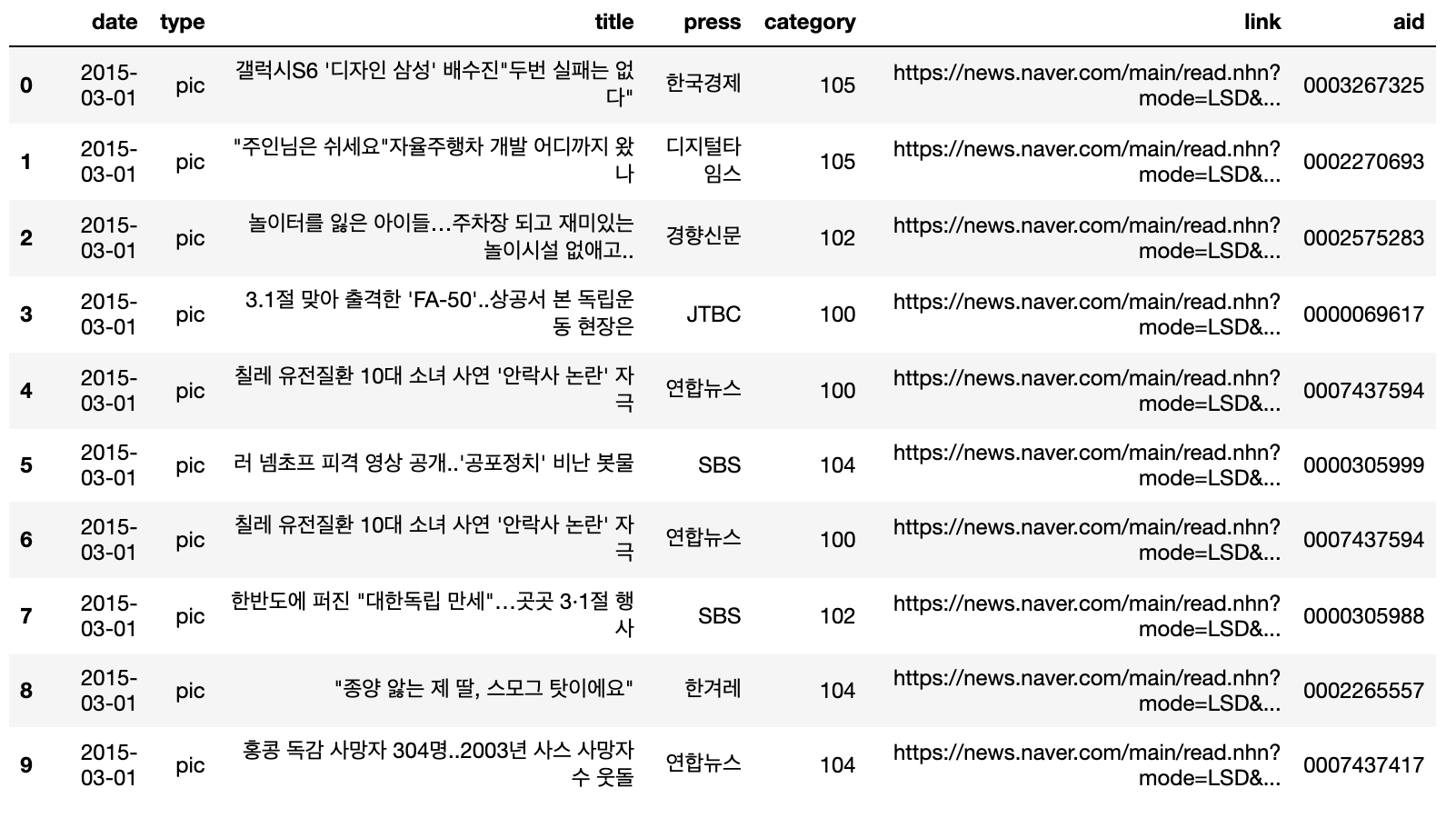
6. 제대로 수집되었는지 csv file을 열어서 확인
# open .csv file
df_naver_news = pd.read_csv('naver_main_news.csv', dtype = {"aid" : "str"})
df_naver_news.head(10)
결과

원래 나와야 할 결과물